![]() Google Scholar is an amazing search tool. Until it breaks.
Google Scholar is an amazing search tool. Until it breaks.
Google harvested an incredible amount of article metadata & abstracts to power Scholar, and it does an impressive job of linking to freely available copies of articles whenever possible. Unfortunately, many of those articles’ full text remains hidden behind paywalls. Luckily, Google included options for libraries to insert links to the full text when our subscriptions contain the articles in question.
But that linking process has proven to be extremely brittle. Earlier this semester, Scholar completely broke for our off-campus users.
Background
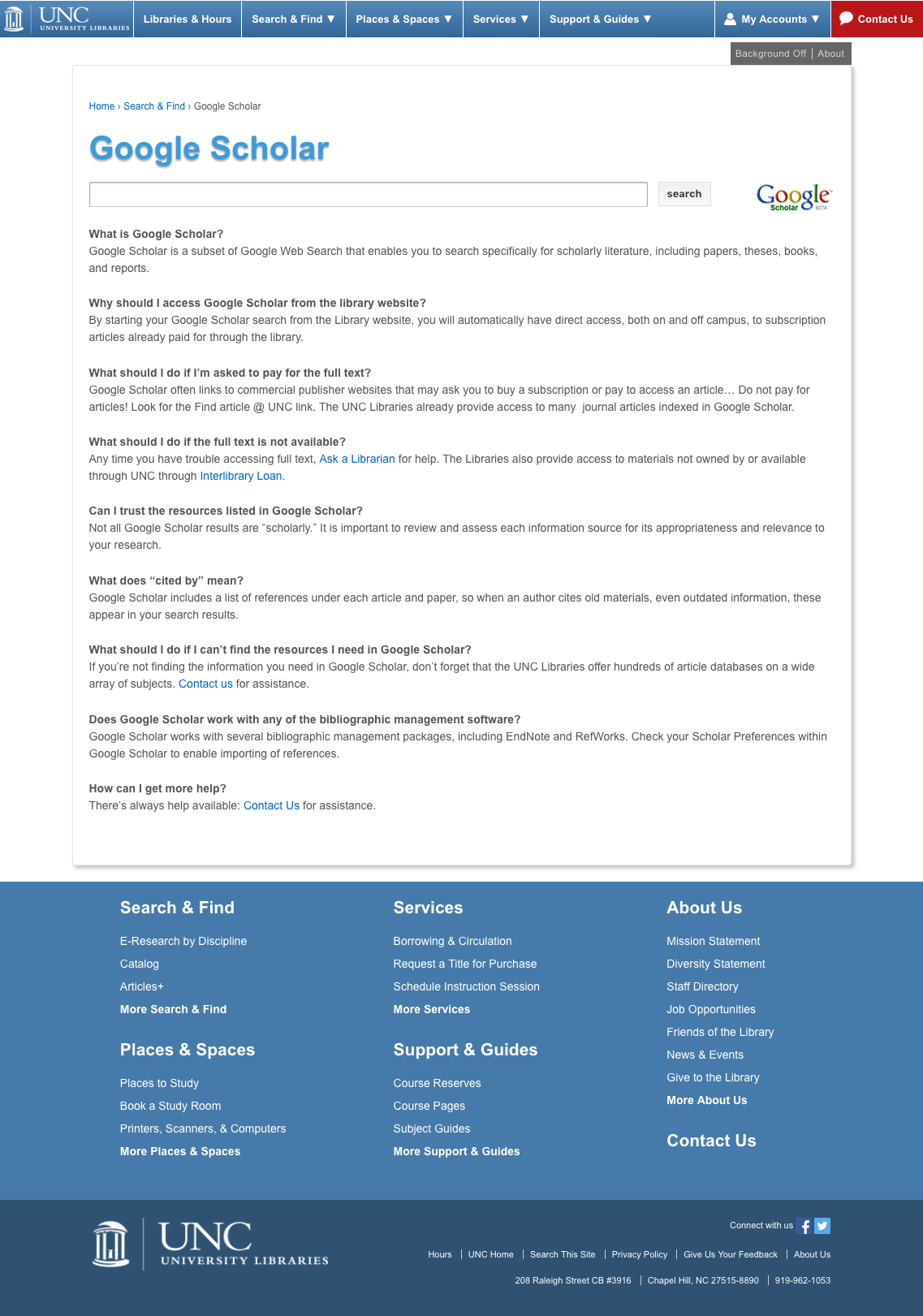 For years we’ve directed our users to a customized Google Scholar search form on our site. The form fed off-campus users through our proxy before they even saw Scholar’s search results. This ensured that every individual article link was also proxied, taking them to the full text via UNC Libraries’ subscriptions instead of hitting paywalls.
For years we’ve directed our users to a customized Google Scholar search form on our site. The form fed off-campus users through our proxy before they even saw Scholar’s search results. This ensured that every individual article link was also proxied, taking them to the full text via UNC Libraries’ subscriptions instead of hitting paywalls.
I should note that this didn’t matter at all for our on-campus users. Their traffic to Scholar always comes from somewhere within our known IP range, so when they get to a paywalled article there’s no proxy needed. But without going through our proxy, off-campus users would have no easy way to get to articles’ full text via Scholar.
The Problem
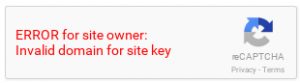 The proxied search form worked great for many years. But it recently broke. Scholar sees all this proxied traffic coming from our proxy’s single IP address, and thinks it’s all coming from one individual user. In July, this started tripping some kind of automated spam protection. After logging into our proxy, users saw a captcha from Google instead of the search results.
The proxied search form worked great for many years. But it recently broke. Scholar sees all this proxied traffic coming from our proxy’s single IP address, and thinks it’s all coming from one individual user. In July, this started tripping some kind of automated spam protection. After logging into our proxy, users saw a captcha from Google instead of the search results.
This wouldn’t be a big deal by itself, but the captcha doesn’t work with a proxy. It just displayed an unhelpful error message: “ERROR for site owner: Invalid domain for site key”. Users had no way to proceed past the captcha to search results, and also no idea what was causing the problem. We got many very understandable questions and complaints from users.
We’re not the only library to face this issue. Dan Scott from Laurentian has a great overview of the problem and just why the proxied captcha fails. It’s also been discussed extensively on the ezproxy listserv, with no solution in sight.
Finding Solutions
We attempted to contact Google about the issue, but have yet to receive a response. After a few days the problem went away – presumably our proxied traffic to Scholar dropped back below some trigger threshold. But during the broken period, our users were frustrated and unable to complete their work.
The problem recurred twice since then, including a particularly unfortunate six days near the beginning of the semester.
Our Options
Assuming no help from Google, we evaluated our options to get users to full text articles from Scholar:
- Proxy all traffic from our search page to Scholar. (This is what we’d been doing)
- Pros: Users will always be delivered to the full text when we subscribe to it, no matter which link they click in Scholar’s results.
- Cons: It breaks at the worst possible times of the semester.
- Put instructions for configuring Google Scholar account settings on our site.
- Pros: This is a very reliable method and sidesteps the proxy problems. After setting it up, users can search from scholar.google.com directly without needing to search via our custom form.
- Cons: Nobody will actually read the instructions. Anybody who doesn’t want to create a Google account is out of luck. Clicking on the title of an article in search results still may go to a paywalled page. You have to click on our resolver link instead.
-
Use a pre-scoped search. Adding an extra parameter to the search form forces Scholar’s results to include “Find Article @ UNC” links to our full-text article access. See how to do it yourself.
- Pros: Users have links to the full-text through our subscriptions. No advance configuration is necessary. The proxy login happens at the time you access an article from the publisher, not when you retrieve search results from Google, so Google won’t flag our traffic as malicious.
- Cons:Off-campus users have to start from our search page every time, and can’t use scholar.google.com directly. As with option 1, clicking on the title of an article in search results still may go to a paywalled page. You have to click on our resolver link instead.
Our Fix
We chose option 3. It has the major benefit of not breaking at peak usage times, which we decided was the most important factor, and also doesn’t require any action on the part of users.
We involved subject librarians and the Libraries’ E-Resources interest group in the decision process, and everyone agreed this was the way to go. We implemented it two weeks ago.
I am not 100% happy with this solution, especially the fact that clicking an article title in the results doesn’t go through our proxy. But it’s the best experience available. I plan on doing follow-up testing to determine how many of our users tend to click on the article title vs the Find @ UNC link. I also regularly attempt to follow up with Google.
Instructions for how to build this type of search form are in a previous post.
Related Usage Data
While we were working on this fix, we also revised and heavily cut down the documentation on our Scholar search page. The old version was quite long and frankly nobody read it.
Stats for /find/googlescholar from 8/22/16 – 11/7/16:
- 26,619 pageviews
- 15,073 searches run
- 140 scrolled to the bottom of the page
Less than .6% of visitors read all the content on the page.
The new version of the documentation is much shorter and focused on two things: How to get to the full text, and how to get help.